
Article 7. Cet article explore deux méthodes efficaces pour caractériser les rôles de vos contacts LinkedIn en utilisant des données préalablement nettoyées.
Il s'agit ici d'identifier les fonctions occupées par les différents contacts dans notre base de données. Pour ce faire, deux méthodes ont été employées :
- Méthode 1 - Récupérer les fonctions déjà définies dans d'autres bases de données,
- Méthode 2 - Définir arbitrairement des rôles en utilisant des expressions régulières pour établir des règles d'attribution.
Je vous encourage également à consulter l'article sur la mise en place d'un environnement de travail ; il vous aidera à mieux comprendre quelles technologies ont été utilisées pour développer ces applications.
Récupération des rôles déjà définis
La première étape consiste à importer nos données nettoyées.
DIR = '/content/gdrive/MyDrive/projetlinkedin/Data'
file = os.path.join(f'{DIR}/DataTraitées/Connections_nettoyées.csv')
df_connections = pd.read_csv(file)
file = os.path.join(f'{DIR}/CarnetsAdresses/Rôle_par_organisations.csv')
df_RolesParOrganisations = pd.read_csv(file)
Fonction regex_mapper
def regex_mapper(df_a_actualiser, df_de_reference, col1, col2):
df_a_actualiser[col2] = pd.Series(dtype=df_de_reference[col2].dtype)
for _, row in df_de_reference.iterrows():
regex_pattern = str(row[col1]).lower()
match_value = row[col2]
mask = df_a_actualiser[col1].astype(str).str.lower().str.contains(regex_pattern, regex=True, na=False)
df_a_actualiser.loc[mask, col2] = match_value
return df_a_actualiser
Cette fonction met à jour un DataFrame (df_a_actualiser) en utilisant un autre DataFrame de référence (df_de_reference) basé sur des correspondances de motifs regex. Pour cela, elle :
- Initialise la colonne : crée une nouvelle colonne dans
df_a_actualiseravec le même type de données que celle dansdf_de_reference. - Boucle sur
df_de_reference: pour chaque ligne dedf_de_reference, crée un motif regex à partir d'une colonne et récupère la valeur correspondante de mise à jour. - Crée un masque en vérifiant si les valeurs de
df_a_actualisercontiennent le motif regex. - Met à jour les valeurs : utilise le masque pour mettre à jour les valeurs dans
df_a_actualiseravec la valeur correspondante dedf_de_reference. - Retourne le DataFrame mis à jour : retourne
df_a_actualiseraprès toutes les mises à jour.
Application de la fonction regex_mapper
df_a_actualiser = df_ConnectionContact
df_de_reference = df_RoleParOrganisation
col1 = 'Organisation'
col2 = 'Rôles'
df_FullContacts = regex_mapper(df_a_actualiser, df_de_reference, col1, col2)
Déterminer des nouveaux rôles
Fonction attribuer_role
La fonction attribuer_role attribue un rôle basé sur des expressions régulières définies. Cela offre une flexibilité pour identifier et classer diverses fonctions professionnelles.
Définition des rôles
regles = {
r'juriste|avocat': 'Juriste',
r'web|veloppeur|full stack|veloper|logiciel': 'Développeur',
r'consultant': 'Consultant',
r'commer|vente|busin|achat|ache|aff|compt': 'Commercial',
r'cyber|syst|inform' : 'Consultants système et cybersécurité',
r'digi|mark' : 'Consultant Digital',
r'coach':'coach',
r'finan|compta|banq|patri': 'Conseiller financier',
r'rh|recrut' : 'Recruteur',
# Ajoutez d'autres règles selon vos besoins
}
Intégrer les rôles dans la fonction
def attribuer_role(row, regles):
if pd.notna(row['Rôles']) and row['Rôles'] != 'Autre':
return row['Rôles']
for regex, role in regles.items():
if re.search(regex, row['Position_Trad'], re.IGNORECASE):
return role
return 'Autre'
Elle attribue un rôle à chaque ligne d'un DataFrame (Row) en fonction de règles régulières prédéfinies (Règle).
Pour cela, elle retourne la valeur de la cellule si celle-ci n'est pas nulle et différente de 'autre'.
Elle itère également sur le dictionnaire de règles établi plus tôt et attribue à chaque valeur du DataFrame le rôle de l'expression régulière correspondante. Elle utilise re.search pour chercher l'expression régulière dans la colonne 'Position_Trad' de manière insensible à la casse (re.IGNORECASE).
Si une correspondance est trouvée, elle retourne le rôle associé.
Si aucune correspondance n'est trouvée après l'application des règles, le rôle 'Autre' est attribué par défaut.
Application de la fonction
df_FullContacts['Rôles'] = df_FullContacts.apply(lambda row: attribuer_role(row, regles), axis=1)
Je vous propose une explication terme à terme de la ligne de code.
df_FullContacts['Rôles']: cible la colonne Rôles dans la DataFrame...apply(): applique une fonction le long de l'axe des lignes (axis=1) de la DataFramedf_FullContacts.lambda row: définit une fonction anonyme (lambda) qui prend une ligne (row) comme argument et appelle la fonctionattribuer_role, en lui passant cette ligne et un ensemble prédéfini de règles (regles).attribuer_role(row, regles): fonction qui analyse une ligne donnée et détermine le rôle basé sur les règles spécifiées.axis=1: indique que l'opération doit être appliquée sur les lignes plutôt que sur les colonnes.
Exploitation des résultats
Une fois nos résultats obtenus, il s'agit maintenant de les rendre lisibles afin que nous puissions les exploiter.
Représentation des résultats sous forme de tableau
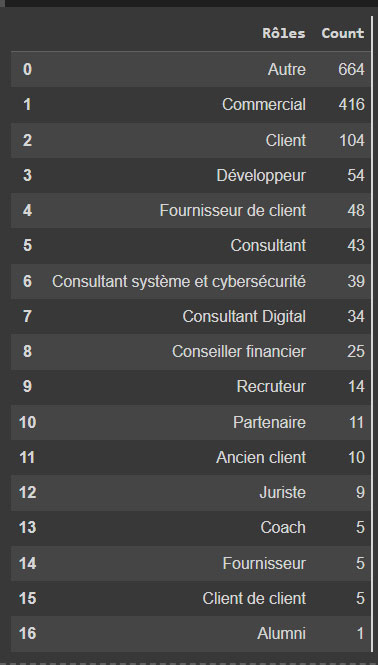
df_role_count = df_FullContacts.groupby('Rôles', dropna=False)['URL'].nunique().sort_values(ascending = False)
df_role_count = df_role_count.reset_index().rename(columns={'URL':'Count'})
Ce petit morceau de code nous permet de trier les résultats. Avec la fonction groupby, nous comptons les URL uniques à l'aide de ['URL'].nunique() et les regroupons par ‘rôles’, en supprimant les valeurs nulles (dropna=False). Ensuite, nous les trions par ordre décroissant avec sort_values(ascending=False).
La deuxième ligne nous permet de réinitialiser la colonne index du tableau et de renommer la colonne URL.
Le tableau final obtenu est le suivant :
Représentation graphique du résultats
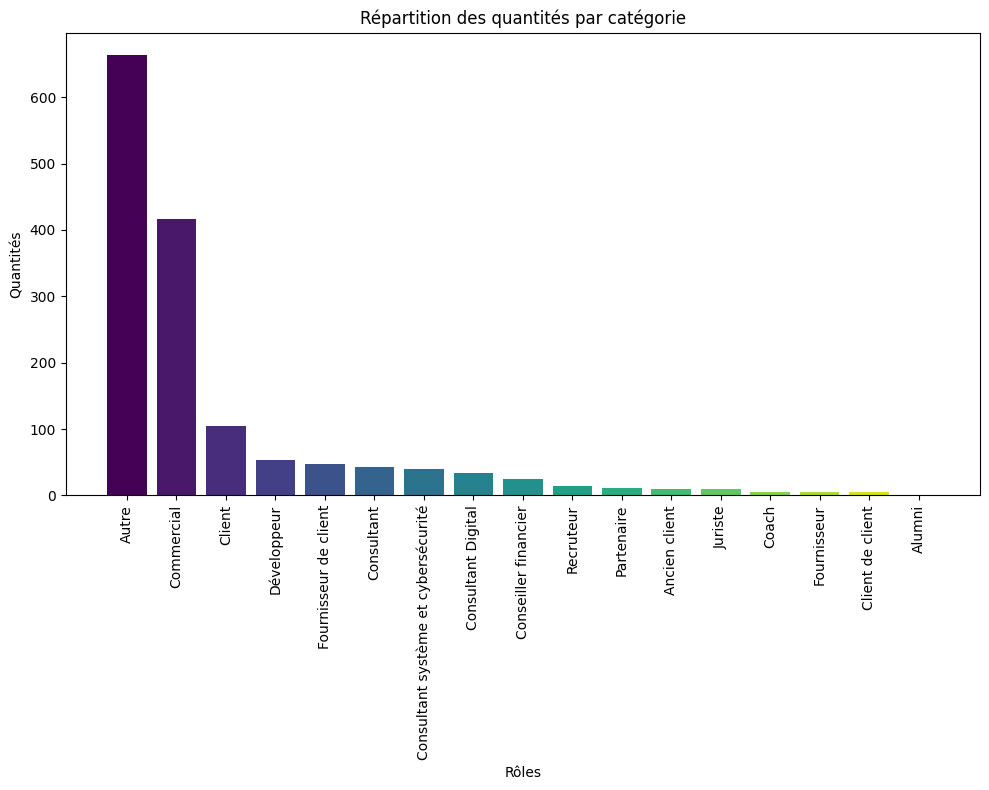
plt.figure(figsize=(10, 8))
colormap = matplotlib.colormaps['viridis']
colors = colormap(np.linspace(0, 1, len(df_role_count['Rôles'])))
plt.bar(df_role_count['Rôles'], df_role_count['Count'], color=colors)
plt.title('Répartition des quantités par catégorie')
plt.xlabel('Rôles')
plt.ylabel('Quantités')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
Nous définissons d'abord la taille du graphique plt.figure(figsize=(10, 8))
Avant de commencer, il est nécessaire de choisir une palette de couleurs appropriée. Ici, nous utilisons viridis, une colormap fournie par Matplotlib. Viridis est l'une des nombreuses colormaps disponibles dans Matplotlib. Elle offre une gamme de couleurs allant du bleu au jaune, reconnue pour sa perceptibilité et son esthétique.
Nous utilisons np.linspace pour attribuer à chaque barre du graphique une teinte distincte, correspondant à une catégorie unique de notre ensemble de données.
Avec ces couleurs et les données disponibles, le code génère un graphique en barres.
Après avoir tracé les barres, le code ajoute des éléments essentiels pour rendre le graphique plus informatif et lisible : un titre au graphique, les noms des axes, et fait pivoter les étiquettes de l'axe des x de 90 degrés pour une meilleure lisibilité.
Enfin, le graphique est affiché en ajustant la disposition pour éviter tout chevauchement :
En conclusion
Cet article a exploré deux méthodes efficaces pour caractériser les rôles des contacts LinkedIn, en utilisant des données préalablement nettoyées. La première méthode consiste à récupérer les fonctions déjà définies dans d'autres bases de données, tandis que la seconde définit arbitrairement des rôles en utilisant des expressions régulières pour établir des règles d'attribution.
Nous avons présenté la fonction regex_mapper, qui joue un rôle crucial dans la mise à jour des rôles des contacts en utilisant des expressions régulières pour faire correspondre et actualiser les informations basées sur une base de données de référence. De plus, la fonction attribuer_role permet une classification cohérente et automatisée des fonctions en attribuant des rôles basés sur des expressions régulières prédéfinies.
L'analyse des données a révélé qu'il reste encore de nombreux rôles à catégoriser malgré les filtres utilisés. Des rôles tels que "dirigeant" ou "fondateur" peuvent être catégorisés en tentant de déduire leur catégorie à travers les champs professionnels des entreprises associées.
En fin de compte, la caractérisation des contacts LinkedIn est une tâche continue qui nécessite une approche flexible et itérative. En utilisant les méthodes présentées dans cet article, les professionnels peuvent mieux comprendre la composition de leur réseau et optimiser leurs interactions pour atteindre leurs objectifs professionnels.