
Article 6. L’idée principale : se concentrer sur l'unification de nos différents répertoires de contacts en créant une seule base de données cohérente.
Unification des carnets d'adresses
La première étape consiste à intégrer les contacts issus de diverses sources (réseau LinkedIn, contacts téléphoniques, e-mail, etc.) dans une unique base de données.
Cela implique d'identifier les contacts communs à travers les différentes plateformes, en utilisant une méthode systématique pour assurer une synchronisation efficace.
La fonction Joindre_contacts
Nous utilisons la fonction Joindre_contacts. Elle permet de fusionner les données en se basant sur des critères définis.
def Joindre_contacts(df_a_actualiser, df_de_reference, colone_de_reference, colone_a_actualiser):
df_a_actualiser[colone_a_actualiser] = df_a_actualiser[colone_de_reference].isin(df_de_reference[colone_de_reference]).map({True: 'oui', False: 'non'})
return df_a_actualiser
Comment elle marche ?
La fonction retient quatre paramètres :
- Le DataFrame que nous souhaitons mettre à jour ;
- Le DataFrame de référence sur lequel nous nous basons ;
- La colonne qui relie ces deux DataFrames ;
- La colonne à mettre à jour ou à créer si nécessaire.
Le principe de la fonction est assez simple. Elle utilise une fonction de Pandas : .isin.
Cette fonction vérifie si une information spécifique est présente à la fois dans le DataFrame cible et dans le DataFrame de référence. Si l'information est commune aux deux, la fonction retourne vrai (oui) ; sinon, elle retourne faux (non).
Voici un exemple d'utilisation
df_a_actualiser = df_connections
df_de_reference = df_ContactsAndroid
colone_de_reference= 'Nom_Complet'
colone_a_actualiser= 'Contact_Telephone'
df_ConnectionContact = Joindre_contacts(df_a_actualiser, df_de_reference, colone_de_reference, colone_a_actualiser)
Après application sur nos différents carnet d'adresses, elles nous renverra un tableau avec les colonnes suivantes :

Préparer l’analyse
Les proportions
D'abord, on commence par calculer les proportions de oui pour chaque type de contact. En gros, on veut savoir, dans chaque catégorie, quel pourcentage de nos contacts sont issus de nos différents carnet d’adresse (physique, téléphonique, mail, etc.).
On filtre chaque colonne (à part la première, d'où le [:, 1:]) pour compter combien de fois on a un oui, et on transforme ça en pourcentage.
proportions = df_visuel.iloc[:, 1:].apply(lambda x: (x == 'oui').mean()*100)
Les scénarios d'interaction
Ensuite, on définit des scénarios spécifiques d'interaction avec nos contacts : certains qu'on a rencontrés en personne, d'autres avec qui on a échangé par téléphone, par mail, et ceux avec qui on n'a pas eu d'interaction directe dans ces catégories.
cond_physique = df_visuel["Contact_Physique"] == "oui"
cond_telephone = df_visuel["Contact_Telephone"] == "oui"
cond_mail = df_visuel["Contact_Mail"] == "oui"
cond_linkedin = (df_visuel["Contact_Physique"] != "oui") & (df_visuel["Contact_Telephone"] != "oui") & (df_visuel["Contact_Mail"] != "oui")
Compter et distinguer
Nous avons donc défini nos scénarios.
Prochaine étape : compter le nombre de contacts de chaque catégorie. On s'intéresse particulièrement à ceux qui apparaissent dans plusieurs catégories.
tous = cond_physique & cond_telephone & cond_mail
phys_tel = cond_physique & cond_telephone
tel_mail = cond_telephone & cond_mail
phys_mail = cond_physique & cond_mail
present_deux = phys_tel | tel_mail | phys_mail
# Calculer le nombre d'individus pour chaque catégorie
nb_tous = tous.sum()
nb_phys_tel = phys_tel.sum() - nb_tous
nb_tel_mail = tel_mail.sum() - nb_tous
nb_phys_mail = phys_mail.sum() - nb_tous
nb_present_deux = present_deux.sum() - (2 * nb_tous)
total_concernes = df_visuel[tous | cond_linkedin].shape[0]
Les pourcentages
Maintenant on peut calculer les pourcentages pour chaque catégorie. On veut connaître, proportionnellement, combien de nos contacts sont hyperconnectés avec nous à travers différents canaux.
pourcentages = [(nb_tous / total_concernes) * 100,
(nb_phys_tel / total_concernes) * 100,
(nb_tel_mail / total_concernes) * 100,
(nb_phys_mail / total_concernes) * 100,
(nb_present_deux / total_concernes) * 100]
Préparation pour le visuel
Finalement, on prépare nos données pour un graphique, histoire de visualiser nos resultats.
categories = ['Tous les contacts', 'Physique & Téléphone', 'Téléphone & Mail', 'Physique & Mail', 'Présent dans deux catégories']
valeurs = [nb_tous, nb_phys_tel, nb_tel_mail, nb_phys_mail, nb_present_deux]
Visualisation des contacts
Pour mieux comprendre la structure de notre réseau, nous emploierons des outils de visualisation tels que Matplotlib.
import matplotlib.pyplot as plt
from matplotlib.ticker import PercentFormatter
La première bibliothèque mentionnée est déjà familière, car nous l'avons précédemment intégrée dans la configuration de notre environnement de travail. La seconde bibliothèque, importée via from matplotlib.ticker import PercentFormatter, est nouvelle pour nous. Elle offre notamment la possibilité de personnaliser nos étiquettes.
Mise en place du graphique
Configurer l'espace de dessin
On définit la taille de notre "toile" virtuelle.
plt.figure(figsize=(18, 6))
Premier graphique : la répartition des contacts
plt.subplot(1, 2, 1)
proportions.plot(kind='bar', color=['blue', 'orange', 'green'])
plt.title('Proportions de chaque type de contact')
plt.ylabel('Proportion (%)')
plt.xlabel('Type de Contact')
plt.xticks(rotation=45)
# Ajouter des étiquettes de pourcentage au-dessus de chaque barre
for i, v in enumerate(proportions):
plt.text(i, v + 0.5, "{:.1f}%".format(v), ha='center', va='bottom')
Dans cette partie, on commence à dessiner.
plt.subplot(1, 2, 1) signifie qu'on va dessiner plusieurs graphiques dans la même figure : ici, on prévoit une ligne, deux colonnes, et on s'attaque au premier emplacement. On dessine un graphique en barres (kind='bar') avec nos données proportions, chacune colorée différemment pour les distinguer facilement. On ajoute ensuite un titre, et on nomme les axes.
plt.xticks(rotation=45) est un petit truc pour incliner les étiquettes des abscisses, rendant le tout plus lisible surtout si on a beaucoup de catégories.
Deuxième graphique : pourcentage d'individus par type de contact
plt.subplot(1, 2, 2)
plt.bar(categories, pourcentages, color=['blue', 'orange', 'green', 'red', 'purple'])
plt.title('Pourcentage d\'individus par type de contact')
plt.ylabel('Pourcentage d\'individus')
plt.xticks(rotation=45)
plt.gca().yaxis.set_major_formatter(PercentFormatter())
# Ajouter des étiquettes de pourcentage au-dessus de chaque barre
for i, v in enumerate(pourcentages):
plt.text(i, v + 0.5, "{:.1f}%".format(v), ha='center', va='bottom')
On passe au deuxième emplacement. Cette fois, on utilise directement plt.bar pour créer un autre graphique en barres, montrant les pourcentages d'individus par type de contact.
plt.gca().yaxis.set_major_formatter(PercentFormatter()) est l'astuce pour formater l'axe des ordonnées en pourcentages, rendant notre graphique encore plus intuitif.
Finale : Affichage
plt.tight_layout()
plt.show()
Les graphiques
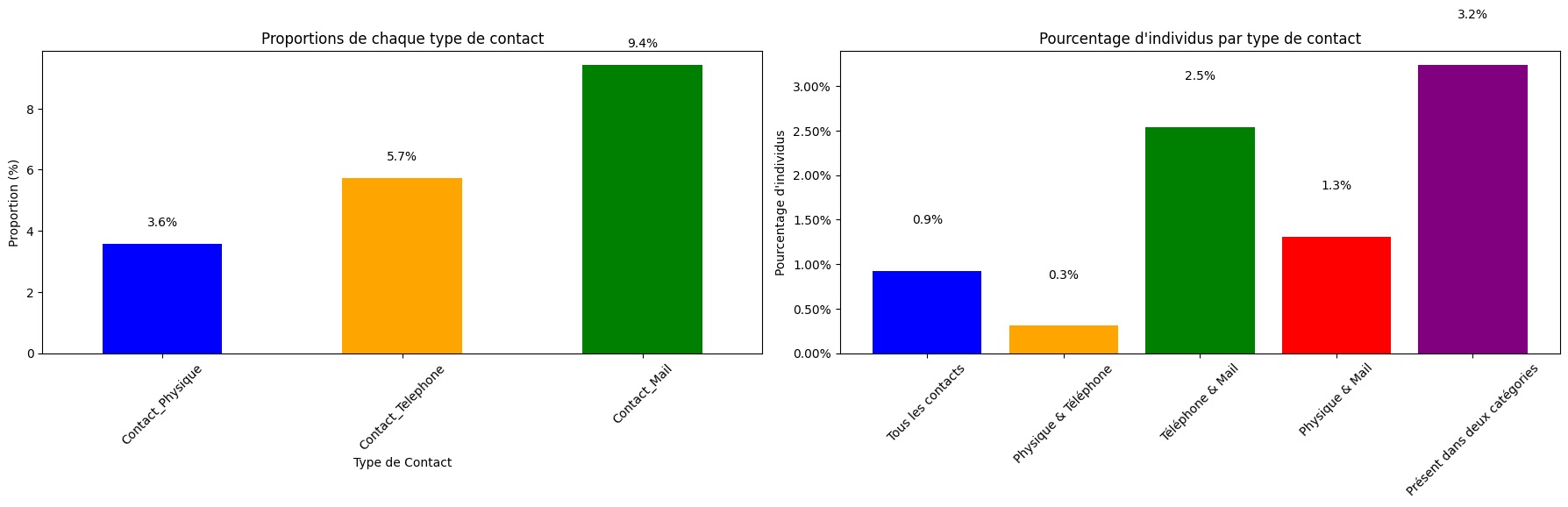
Analyse des graphiques
Globalement, ces graphiques montre que peu des contacts des autres carnets d'adresses se retrouvent aussi dans le réseau LinkedIn
Ils reflètent un réseau professionnel où les interactions numériques prédominent par rapport aux rencontres physiques ou aux appels téléphoniques. Ils montrent aussi des relations multi-canal avec une petite fraction de du réseau. Pour un professionnel moderne, cela n'est pas inhabituel, étant donné la nature souvent virtuelle de nos réseaux sociaux professionnels.
Si l'objectif est de renforcer les liens, les données suggèrent une opportunité d'accroître les interactions physiques et téléphoniques pour construire un réseau plus étroitement connecté.
Pour conclure
Pour envelopper notre périple dans le monde des données LinkedIn, nous avons fait plus que simplement trier et compter. Nous avons exploré les profondeurs de notre réseau professionnel, et les graphiques nous ont révélé les histoires cachées derrière les chiffres. La répartition des types de contacts nous a montré que le monde digital domine nos interactions, avec les mails comme principale forme de communication.
Malgré la commodité des emails, il est clair que la connexion personnelle, que ce soit par une poignée de main ou une conversation téléphonique, reste rare mais précieuse. Cela souligne un potentiel inexploité pour approfondir les relations existantes et peut-être, pour en construire de nouvelles plus solides.
De plus, notre plongée dans les pourcentages d'individus par type de contact révèle que la polyvalence est un trait moins commun dans nos connexions. Les personnes avec qui nous avons échangé à travers multiples canaux sont peu nombreuses, indiquant que nos interactions tendent à rester dans des sphères définies.
En somme, ce billet n'est pas qu'un simple exposé de chiffres. C'est un appel à l'action. C'est le moment idéal pour réfléchir à la façon dont nous interagissons avec notre réseau et à l'impact que nous souhaitons avoir. En exploitant ces données, nous pouvons stratégiquement orienter nos efforts pour forger des liens plus forts et plus significatifs. Alors, prenons ce savoir nouvellement acquis et utilisons-le pour enrichir notre toile professionnelle. Car après tout, chaque contact est une porte vers de nouvelles opportunités, et chaque interaction est un pas de plus vers une collaboration fructueuse.