
Article 4. Première utilisation de fonctions simples comprises dans Panda.
Premiers résultats sur le compte LinkedIn d’un consultant ISITIX
DIR = '/content/gdrive/MyDrive/nom_du_projet'
file = os.path.join(DIR, 'Connections.csv')
df_connection = pd.read_csv(file)
Avant le nettoyage des données
Avant de procéder au nettoyage des données, nous avons analysé le champ "position" extrait de la base de contacts LinkedIn : Connections.csv, composée d'environ 1500 entrées. Notre première étape a consisté à évaluer le nombre de mots (tokens) formant l'intitulé de poste de chaque contact.
| Nombre de tokens | Poste du contact |
| 1 | CTO |
| 2 | Directeur général |
| 4 | Chief Information Security Officer |
| 7 | Directeur des ventes et du développement commercial |
| 13 | Psychologue du travail - Contrôleur de sécurité (en cours d'agrément) - Référente RPS PDL |
Diviser pour compter
Dans notre analyse du champ "position" nous segmentons les descriptions en mots individuels, utilisant pour cela les fonctions str.split() et str.len(). Cette première étape décompose chaque titre en éléments analysables, que nous regroupons ensuite et en triant ces éléments par nombre de mots, grâce à la fonction groupby(). Une fois organisé en fréquence décroissante, le tri des données nous révèle les quantité de mots les plus utilisés.
df_connection['Nombre_de_token'] = df_connection['Position'].str.split().str.len()
df_Position_NbrToken = df_connection.groupby('Nombre_de_token')['URL'].nunique().sort_values(ascending=False).reset_index()
df_Position_NbrToken = df_Position_NbrToken.rename(columns={'URL': 'Count'})
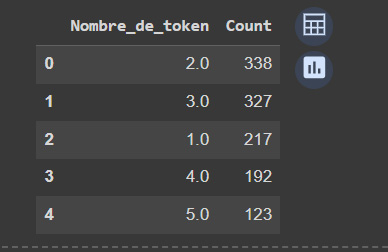
df_Position_NbrToken.head()
La phase finale de notre processus consiste à renommer les colonnes pour une meilleure lisibilité et présentation. Ce qui nous donne le résultat suivant :
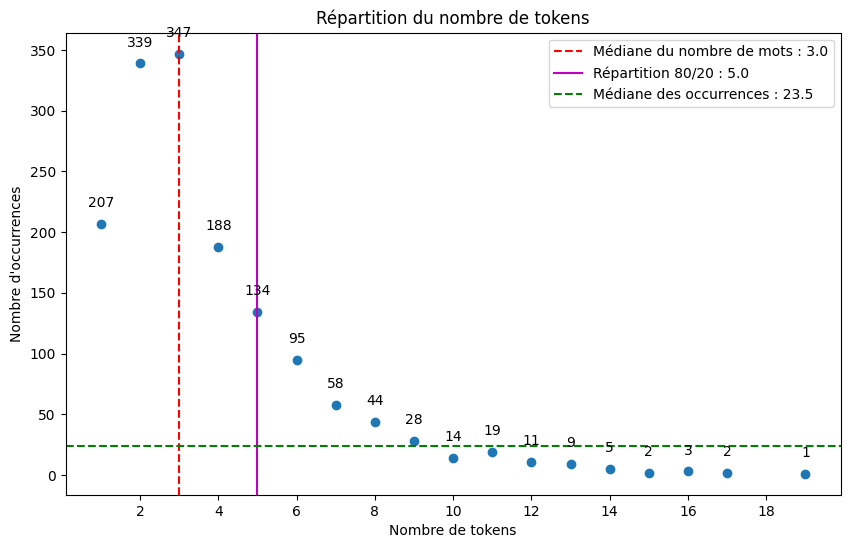
Une fois les données obtenues, on détermine un certain nombre de médianes.
mediane_longueur = df_connection['Nombre_de_token'].median()
val_80 = df_connection['Nombre_de_token'].quantile(0.8)
mediane_occurence = df_Position_NbrToken['Count'].median()
Une fois les données médianes obtenues nous pouvons passer à l'élaboration du graphique nous utilisons pour ça la bibliothèque panda matplotlib.pyplot que nous avions installé plus tôt.
Le graphe : une image vaut mille mots
La figure : définir les dimensions
Tout commence par la création d'une "toile" sur laquelle nous allons construire notre graphique. Pour Matplotlib, cela se traduit par la création d'une figure.
plt.figure(figsize=(10, 6))
Cette ligne crée une nouvelle figure avec une taille spécifiée de 10 pouces par 6 pouces.
Localisateurs d'axe : s'assurer que chaque détail compte
Pour obtenir un graphique aussi précis et informatif que possible, nous utilisons des localisateurs d'axe. Ils permettent d’ajuster les marques sur l'axe des x :
from matplotlib.ticker import MaxNLocator
Cette instruction garantit que l'axe des x n'affichera que des valeurs entières. C’ est essentiel lorsque nous travaillons avec des données qui n'ont de sens que sous forme d'entiers, par exemple avec le nombre de tokens.
Lignes verticales et horizontales : souligner les informations clés
Nous ajoutons ensuite des lignes verticales et horizontales pour mettre en évidence des statistiques clés, comme la médiane du nombre de tokens et la médiane des occurrences. Chaque ligne est codée par couleur et style pour une distinction facile :
plt.axvline(x=mediane_longueur, color='r', linestyle='--', label=f'Médiane du nombre de mots: {mediane_longueur}')
plt.axvline(x=val_80, color='m', linestyle='-', label=f'Répartition 80/20 : {val_80}')
plt.axhline(y=mediane_occurence, color='g', linestyle='--', label=f'Médiane des Occurences: {mediane_occurence}')
Points et annotations
Le cœur de notre graphique est le nuage de points. Il représente la relation entre le nombre de tokens et leur fréquence d'occurrence. Chaque point est également annoté pour fournir des informations supplémentaires.
plt.scatter(df_Position_NbrToken['Nombre_de_token'], df_Position_NbrToken['Count'])
Nous parcourons ensuite chaque point pour ajouter une annotation textuelle, ajustant soigneusement le positionnement pour une lisibilité optimale.
for i, txt in enumerate(df_Position_NbrToken['Count']):
plt.annotate(txt,
(df_Position_NbrToken['Nombre_de_token'].iat[i], df_Position_NbrToken['Count'].iat[i]),
textcoords="offset points", # Position relative
xytext=(0,10), # Décalage du texte en points
ha='center', # Alignement horizontal au centre
va='bottom') # Alignement vertical en bas (au-dessus du point)
Titre, étiquettes, et légende
Aucune visualisation n'est complète sans un titre descriptif et des étiquettes d'axe claires. Nous ajoutons également une légende pour aider à interpréter les lignes spéciales.
plt.title('Répartition du nombre de tokens')
plt.xlabel('Nombre de Tokens')
plt.ylabel('Nombre d\'Occurences')
plt.legend()
Le graphique
Finalement, après avoir construit notre graphique avec soin, nous le révélons au monde :
plt.show()
En conclusion
La description des postes LinkedIn varient beaucoup en longueur : entre un seul mot à dix-huit mots.
De nombreux utilisateurs de LinkedIn choisissent d'élargir délibérément la description de leur poste. Cette stratégie vise à se distinguer et à fournir une explication plus détaillée de leurs responsabilités professionnelles. Cette tâche semble souvent ardue à accomplir en quelques mots dans le contexte professionnel actuel, où les rôles et fonctions tendent à devenir de plus en plus nuancés.
Contrairement à une carte de visite, LinkedIn offre une plateforme permettant à certains de ses utilisateurs de se démarquer en personnalisant leur titre professionnel, mettant en avant une approche plus détaillée et réfléchie de leur position.