
Article 3. Après avoir nettoyé notre document, l'étape suivante pour optimiser notre analyse de texte consiste à lemmatiser et tokeniser notre corpus.
Ces processus affinent le texte pour une analyse plus précise et significative. Voyons comment cela fonctionne.
La lemmatisation avec SpaCy
Que signifie lemmatiser ?
La lemmatisation est l'acte de ramener un mot à sa forme de base ou de dictionnaire. Cela nous permet d'uniformiser les variations d'un mot pour une analyse cohérente.
La fonction Lemmatiser utilise la puissance de SpaCy pour traiter le texte français, identifiant la forme de base des mots tout en filtrant les nombres qui pourraient fausser notre analyse.
def Lemmatiser(doc):
myDoc = nlpFR(doc)
myLemmatizeDoc = " ".join([token.lemma_ for token in myDoc if not token.like_num])
print(myLemmatizeDoc)
return myLemmatizeDoc
Comment fonctionne la lemmatisation ?
- Initialisation : on commence par appliquer notre modèle de langue français, nlpFR, au texte. Cela transforme le texte en un objet contenant des tokens et leurs annotations linguistiques.
- Filtrage et lemmatisation : on itère ensuite sur chaque token, excluant les nombres grâce à token.like_num et récupérant la forme lemmatisée des mots restants.
- Reconstruction : les lemmes sont rassemblés en une chaîne de caractères, nous offrant une version épurée et normalisée du texte.
La tokenisation : découper le texte en petits morceaux
Qu’est-ce que la tokenisation ?
La tokenisation est un processus qui découpe le texte en mots ou symboles, facilitant ainsi l'analyse du contenu.
La fonction tokenisation prend une colonne de notre DataFrame et la transforme en une liste de mots individuels.
def tokenisation (df):
texte_complet = ' '.join(df.astype(str).tolist())
mots = word_tokenize(texte_complet)
return mots
Étapes-clés
- Préparation : on transforme d'abord notre colonne de DataFrame en une longue chaîne de texte. Il est nécessaire de s'assurer que chaque élément est converti en chaîne de caractères.
- Utilisation de
word_tokenize: on divise ensuite cette chaîne en une liste de tokens, permettant une analyse mot par mot de notre document.
Pourquoi la lemmatisation et la tokenisation sont-elles cruciales ?
La lemmatisation et la tokenisation sont des étapes fondamentales dans le traitement du langage naturel. Elles permettent de :
- Réduire la complexité du texte, facilitant l'identification des tendances, des motifs et des anomalies. On élimine les variations inutiles, qui compliquent l'analyse, en ramenant les mots à leur forme de base.
- Comprendre la structure et la composition du texte, en ouvrant la porte à des analyses plus sophistiquées comme la fréquence des mots, la collocation, et bien plus encore.
- Poser les bases d’une exploration de données riches et nuancées en intégrant ces processus dans notre pipeline d'analyse de texte.
- Dégager des insights précis et actionnables à partir de notre corpus.
C'est une étape non négligeable pour tout projet d'analyse de texte visant la précision.
Première analyse
Nous avons utilisé notre méthode pour analyser le champ "position" de la table de contacts de LinkedIn : connection.csv. La base de données utilisée comprend approximativement 1500 contacts.
Avant le nettoyage des données
L'objectif était de décomposer et d'examiner le nombre de mots (tokens) composant la désignation professionnelle d'un utilisateur. Voici quelques exemples illustrant notre approche :
| Intitulé désignant une fonction | Nombre de mots |
| Psychologue du travail - Contrôleur de sécurité (en cours d'agrément) - Référente RPS PDL | 13 |
| Directeur des ventes et du développement commercial | 7 |
| Chief Information Security Officer | 4 |
| Directeur Général | 2 |
| CTO | 1 |
Cette démarche nous permet d'analyser la complexité et la variété des intitulés de postes au sein de notre base de données LinkedIn. Elle offre une vue d'ensemble sur les professions, leurs intitulés et leurs catégories.
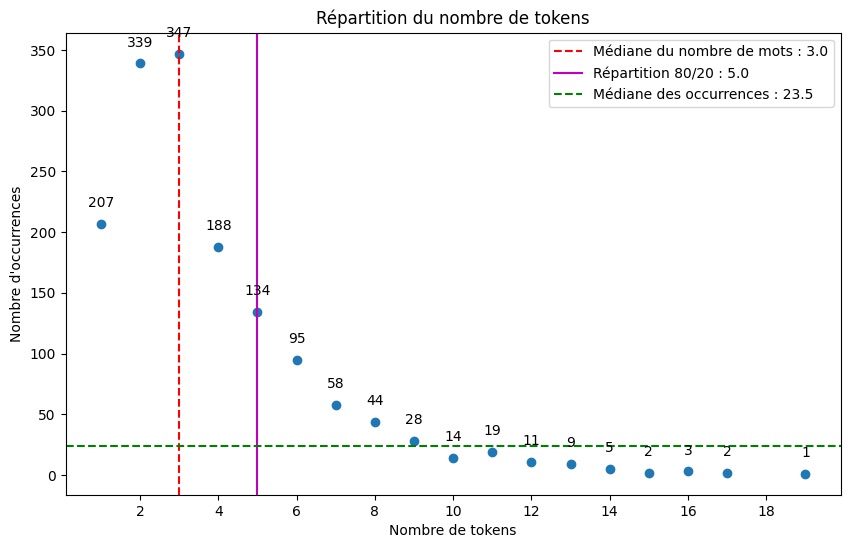
L'analyse a révélé une grande variabilité dans la longueur des descriptions des postes sur LinkedIn, allant d'un seul mot à dix-huit mots. Cette première observation suggère que de nombreux utilisateurs de LinkedIn choisissent d'élargir délibérément la description de leur poste. Cette stratégie vise à se distinguer et à fournir une explication plus détaillée de leurs responsabilités professionnelles, une tâche souvent ardue à accomplir en quelques mots dans le contexte professionnel actuel, où les rôles tendent à devenir de plus en plus nuancés. Contrairement à une carte de visite, LinkedIn offre une plateforme permettant à certains de ses utilisateurs de se démarquer en personnalisant leur titre professionnel, mettant en avant une approche plus détaillée et réfléchie de leur position.
Après avoir nettoyé les données
Nous avons examiné les mots clés les plus fréquemment utilisés. Notre deuxième constatation est que l'analyse de ces mots clés peut révéler des aspects de votre profil socio-professionnel. Cela offre également l'opportunité de repenser votre stratégie de mise en réseau. Vous pourriez envisager d'augmenter la présence de mots clés liés à un secteur spécifique (comme la sécurité ou la technique), à une fonction (telles que les finances), ou à un niveau hiérarchique (comme fondateur), selon vos objectifs professionnels.
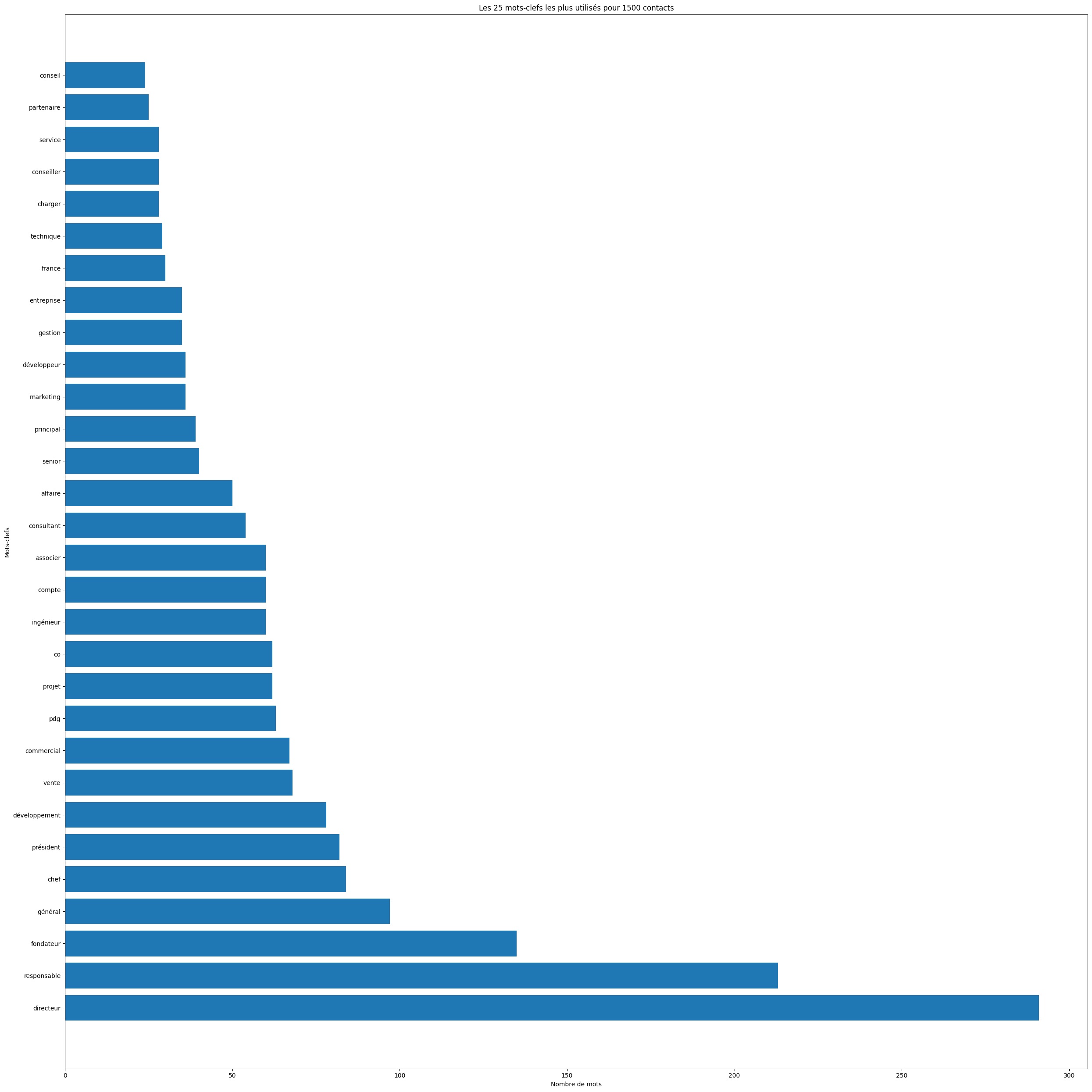
Conclusion
Nous avons parcouru ensemble le chemin allant de l'installation de notre espace de travail jusqu'à la définition de fonctions clés essentielles à l'analyse de nos dataframes, jusqu’à la présentation des premiers résultats de notre analyse.
Dans les articles suivants, nous allons approfondir la méthodologie employée. Nous précisons également notre travail sur le traitement de nos données.